Resumen del capitulo 2 Procesos e Hilos
Procesos
Creación de un proceso
- Hay cuatro eventos que provocan la creación de un proceso:
- Arranque del sistema (Arranque)
- Un proceso hace una llamada al sistema para que cree un proceso (subproceso)
- Un usuario abre un programa (desde el Shell)
- Un trabajo por lotes inicia un proceso de la lista (#Proceso batch en un mainframe)
Terminación de un proceso
- Hay cuatro formas de terminar un proceso
- Salida normal voluntaria (error 0)
- Salida por error voluntaria (error distinto)
- Error fatal (involuntaria)
- Cuando el proceso ejecuta una instrucción ilegal, puede finalizar o indicar al SO que se encargará de la excepción
- Eliminado por otro proceso (involuntaria)
- Esto sucede cuando un proceso con permisos, llama a
killsobre él
- Esto sucede cuando un proceso con permisos, llama a
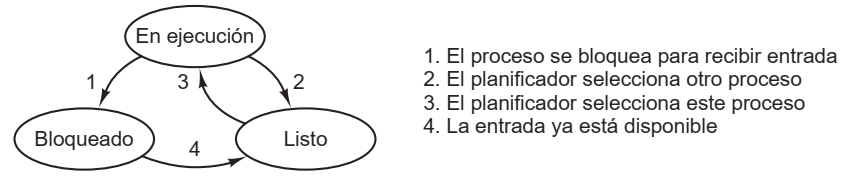
Estados
- Un proceso puede bloquearse cuando está esperando una entrada que no está disponible, y por lógica no puede avanzar
- Ej.: "
cat cap1 cap2 cap3 | grep abc: Grep está bloqueado esperando hasta que Cat le envíe su salida"
- Ej.: "
- También podría estar listo para ejecutarse, pero está inactivo hasta que el SO le asigne el CPU
- Finalmente, puede estar en ejecución
Implementación de procesos
- Tabla de procesos: Un arreglo de estructuras (bloques de control de procesos) con todos los datos del proceso que deban ser guardados cuando este cambia de estado
- Se guardan cosas como los archivos abiertos, puntero de stack, program counter, PSW, etc.
Modelado de Multiprogramación (cálculo de performance)
- Si un proceso realiza cálculos 20% del tiempo que se ejecuta, ¿5 procesos mantendrían el CPU en 100%? No, pues nunca estarían esperando E/S
- Se modela entonces la CPU desde la probabilidad
- Un proceso gasta
tiempo esperando E/S - Hay
procesos en ejecución - La probabilidad de que todos los
procesos estén esperando E/S a la vez (la CPU estaría inactiva) es: - El uso de la CPU se calcula como $$\text{Uso de CPU} = 1-p^n$$
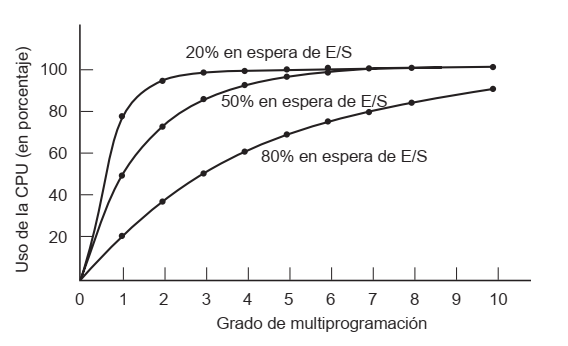
- En el caso de un programa que espera 80% del tiempo en E/S, necesita 10 procesos para que el desperdicio de CPU sea menor a 10%
- Un proceso gasta
Hilos
- La razón principal de tener hilos es que un programa realiza varias acciones a la vez que necesitan compartir los datos en todo momento (los hilos comparten el espacio de memoria)
- Crear hilos es mucho (10 a 100 veces) más rápido que crear procesos
- Habilitan procesos secuenciales que realizan llamadas al sistema (syscalls) con bloqueo y aun así logran paralelismo.
Modelo
- Si un proceso es una agrupación de ciertos recursos (variables, archivos, registros) y una entidad que el SO planifica, un hilo es una ejecución paralela dentro de ese proceso (o entorno de recursos)
Aún así, todos los hilos comparten el mismo espacio de memoria del proceso, pero cada hilo tiene su propio program counter, stack, PSW y registros. - Los CPUs tienen multihilamiento por hardware que permite conmutar los hilos en cuestión de nanosegundos
- Al igual que un proceso, el hilo también puede estar en uno de los 3 estados: Bloqueado, Listo, Ejecutando
- Los hilos introducen complicaciones de diseño:
- ¿Debería
forkcrear copias de los hilos del padre? ¿Los hilos bloqueados siguen bloqueados una vez bifurcado? etc. - ¿Qué pasa si dos hilos detectan, a la vez, poca memoria y deciden reservar más? Se reservaría dos veces la memoria (un caso de #Condiciones de carrera).
- ¿Debería
[#Comparación entre procesos e hilos]
Hilos en modo de usuario
La técnica de hilamiento se implementa en una biblioteca del software de terceros
- Cada proceso necesita su tabla de hilos propia, donde se guardan los datos de cada hilo (PC, Stack Pointer...) cuando el hilo cambia de estado
- Tienen soporte en los SO sin multihilamiento
- Cada procesos puede tener un algoritmo de planificación personalizado para la multiprogramación de sus hilos
- Escalan mejor que los hilos de kernel
- Un hilo que realice una syscall para bloquear el proceso afecta a todos los demás hilos
- Un hilo puede producir fallos de página
- Mientras se ejecute un hilo, ningún otro pude correr hasta que este ceda el CPU
Hilos en modo monitor (kernel)
- El lugar de una tabla de hilos por proceso, hay una tabla global en la memoria del kernel con la misma información
- Cuando un hilo se bloquea, el kernel puede ejecutar un hilo del mismo proceso o de otro
- En cambio, un hilo de modo usuario ejecutaría hilos de su proceso, de a uno, hasta que se le expropie la CPU
- Crear y eliminar hilos en el kernel es más costoso, por lo que se reusan:
- Cuando se destruye un hilo, se marca como no ejecutable, pero no se borra su estructura de datos de la memoria
- Para "crear" un hilo nuevo, se reactiva uno anterior y se cargan los nuevos datos ahí
Comunicación entre procesos
Condiciones de carrera
El resultado de que dos o más procesos/hilos lean/escriban datos, dependerá de quién se ejecutó primero
- Región crítica: La parte del programa que accede a memoria compartida y necesita cuidarse de las condiciones de carrera
- Condiciones generales para evitarlas:
- Sólo puede haber 1 proceso en su sección crítica a la vez
- No se pueden hacer suposiciones sobre el CPU (velocidad o cantidad)
- Fuera de su región crítica, un proceso no puede bloquear a otros
- La espera para entrar a una región crítica nunca puede ser infinita
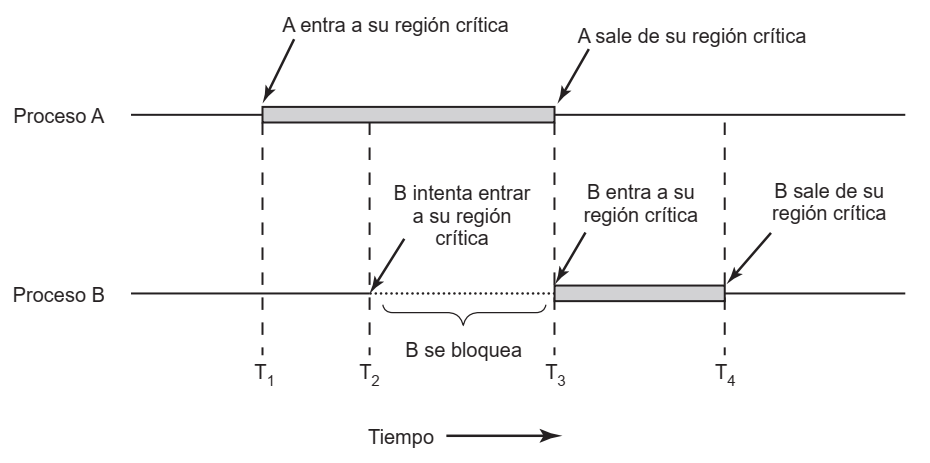
Exclusión mutua (Mutex) con espera ocupada
Métodos para evitar condiciones de carrera
Deshabilitar interrupciones
- Sólo funciona en un sistema con 1 CPU
- Como la multiprogramación funciona en base a interrupciones de reloj, deshabilitar las interrupciones durante las regiones críticas evitaría que la CPU salga del proceso
- Desventaja: En un sistema multiprocesador, sólo se deshabilitarían las interrupciones para 1 CPU, no todos. No se evitaría nada.
Variables candado
- Es una variable en memoria compartida con valor
1o0 - Antes de entrar en una región crítica, el proceso A verifica que sea
0, entra y la pone en1- Si fuera
1, sólo espera a que sea0(con espera ocupada)
- Si fuera
- Desventaja: Entre que comprueba la variable y la cambia, puede haber una planificación de proceso, entonces 2 procesos entran a sus regiones a la vez
Mutex SIN espera ocupada
Dormir y despertar
- Se usan las llamadas
sleepywakeup - Ambas syscalls tienen un parámetro para asociar direcciones de memoria: asocia las llamadas a sleep con una función, y asocia las llamadas a wakeup con otra
Semáforos
- Consta de una variable tipo
int, y las operacionesdownyup- El semáforo siempre es
y representa el número de señales de despertar pendientes
- El semáforo siempre es
down: Si el semáforo es > 0 disminuye el valor y sigue- Si es = 0, el proceso se pone a dormir sin completar al operación
up: Incrementa el valor del semáforo. Luego, si hay procesos inactivos en ese semáforo (detenidos en undown), se selecciona uno al azar y se permite completar su operacióndown- Las operaciones son atómicas, es decir que al mismo tiempo se comprueba la variable, se modifica y se pone a dormir el proceso. Esto es esencial para evitar las condiciones de carrera.
Planificación
Se realiza cuando hay más de un proceso en estado Listo para un CPU.
El planificador es la parte del SO que realiza la decision con un algoritmo de planificación.
- Dividimos los procesos en dos tipos:
- Limitados por cálculo: Invierten más tiempo procesando cálculos que E/S
- Limitados por E/S: Tienen muchas ráfagas cortas de procesamiento y gastan más tiempo en E/S
- La planificación ocurre en cuatro ocasiones:
- Cuando se crea un nuevo proceso y se decide entre ejecutar el padre o el hijo
- Cuando un proceso termina
- Cuando un proceso se bloquea
- Aveces en una interrupción de E/S
- Los algoritmos de planificación se dividen en:
- No apropiativo: Selecciona un proceso para ejecutar y lo deja hasta que se bloquee o libere el CPU por su cuenta. No decide durante las interrupciones de reloj.
- Apropiativo: Manda un proceso a correr por un tiempo finito, y lo devuelve al estado Listo forzadamente cuando ocurre la interrupción de reloj correspondiente
- Y se categorizan según el entorno con distintas metas:
- Todos los sistemas
- Equidad: Repartir justamente la CPU a los procesos
- Políticas: Verificar que se lleven a cabo
- Balance: Mantener ocupadas todas las partes del sistema
- Procesamiento por lotes: No hay usuarios esperando en las terminales; se permiten los algoritmos no apropiativos
- Rendimiento: Maximizar los trabajos completados por hora
- Tiempo de retorno: Minimizar el tiempo de ejecución
- Maximizar el uso de CPU
- Interactivos: La apropiación es esencial
- Responder a todas las peticiones rápido
- Proporcionalidad: Cumplir expectativas
- De tiempo real: La apropiación no es necesaria pues los procesos saben que no pueden ejecutarse por periodos largos
- Cumplir los plazos sin perder datos
- Predictibilidad: Evitar la degradación de calidad en sistemas multimedia
- Todos los sistemas
Algoritmos de planificación
Para sistemas de procesamiento por lotes
- FCFS (First come, first served): No apropiativo
- SJF (Shortest job first): No apropiativo
- SRTN (Shortest return time next): Apropiativo
- Debe conocer el tiempo de ejecución de antemano
Para sistemas interactivos
- Round-Robin/Turno circular
- A cada proceso se le da un tiempo (quántum) para ejecutarse. Si para cuando el quantum termina el proceso sigue en ejecución, la CPU es apropiada para otro proceso
- Si el proceso se bloquea/termina antes, la conmutación ocurre en ese momento
- Planificación por prioridad
- A cada proceso se le da una prioridad y se ejecuta el más alto
- El planificador puede bajarle la prioridad en cada interrupción de reloj, y si resulta menor que el siguiente proceso más importante, se conmuta
- Proceso más corto siguiente
- Se estima según el comportamiento anterior y se ejecuta el que se suponga más corto
- Planificación garantizada
- El sistema promete un rendimiento y para cumplirlo, ajusta los ciclos de CPU de cada proceso según la potencia que cada uno requirió (como el algoritmo anterior)
- Planificación por sorteo (Random)
- Planificación por partes equitativas
- A cada usuario se le asigna una fracción de CPU y el planificador selecciona procesos para cumplir
Para sistemas en tiempo real
- Estos sistemas se dividen en:
- Tiempo real duro: Los límites de tiempo son absolutos
- Tiempo real suave: Las tardanzas son aceptables
- Para planificar, se divide el programa en varios procesos donde el comportamiento y el tiempo de ejecución de cada uno son predecibles
- Puede responder a eventos periódicos (de intervalo regular) o aperiódicos (impredecibles)
- Algoritmos estáticos: Toman decisiones de planificación antes de que el sistema se ejecute
- Algoritmos dinámicos: Deciden durante la ejecución
Política contra mecanismo
- Los planificadores no saben cuál de los hijos de un proceso es más conveniente ejecutar, por lo que se separa el mecanismo de planificación de la política de planificación.
- Es decir, el algoritmo tiene ciertos parámetros que los procesos pueden completar
- Por ejemplo, un algoritmo por prioridad del kernel provee una syscall para modificar las prioridades de un (sub)proceso.
Planificación de hilos
- Con hilos a nivel de usuario, un proceso podría ser expropiado de la CPU sin que se ejecuten todos sus hilos justamente, pero el planificador del proceso podría hacer un uso más eficiente
- Con hilos a nivel de kernel, se nivelan los tiempos entre todos los hilos de todos los procesos, pero el cambio de contexto que esto implica es muy costoso
Anexos
Notas relacionadas
Definiciones previas, abreviaturas
- E/S = I/O = Entradas y/o Salidas
- Mutex = Exclusión mutua
- Syscall = Llamada al sistema (instrucción que envía una señal al kernel)
Una instancia en ejecución de un programa, incluyendo sus valores de registros (Program Counter, Registros, Variables)
El proceso es distinto del programa, pues el programa sólo es el código que se carga en memoria para crear un proceso.
Un proceso es a un programa lo que un objeto es a una clase.
Es un modus operandi en el que el sistema operativo alterna muy rápidamente la ejecución de varios procesos para aparentar que se ejecutan en paralelo.
De otra forma, el SO multiplexa el CPU en el tiempo entre varios procesos, pues un sólo CPU (un núcleo) puede ejecutar un proceso a la vez.
Es un arreglo de estructuras donde, para cada ID de señal de interrupción, se guarda un puntero en memoria a un procedimiento que la maneja.
Es un puntero a un procedimiento en C (parte del software de un device driver) encargado de manejar una señal de interrupción que un dispositivo le envía al CPU.
El CPU recibe una interrupción del dispositivo A con señal S, el hardware de interrupción busca en la Tabla de Vectores de Interrupción qué dirección D corresponde al programa en memoria que maneja la señal S, y se coloca D en el Program Counter del CPU.
Proceso batch
En los mainframes, se usa un sistema de procesamiento por lotes en el que los usuarios envían trabajos de procesamiento (en remoto), y cuando el SO decide que tiene los recursos para ejecutar un trabajo, crea un proceso y ejecuta el siguiente en la cola.
Creación de un subproceso y jerarquía
En UNIX
Un proceso llama la función fork, que crea un clon exacto en memoria. Luego, el hijo llama a execve para cargar un programa del disco y cargarlo en su espacio de memoria. Este proceso en 2 pasos permite que los procesos se compartan los flujos estándar (stdin, stdout, stderr).
En el arranque
El programa init se encarga de crear subprocesos para cada terminal (y de ahí, cada usuario creará sus subprocesos).
- Es decir,
inites el programa de mayor jerarquía.
En Windows
No se admiten procesos hijos. Un proceso puede llamar a CreateProcess con varios parámetros, y devuelve un handler para que el padre pueda controlar al hijo, pero en definitiva todos los procesos tienen el mismo nivel.
- Windows no tiene jerarquía de procesos
Funcionamiento de un servidor web
- El servidor es un proceso con un hilo despachador y varios hilos trabajadores
- El despachador sólo espera peticiones de la red, toma decisiones sobre ellas (enrutamiento, qué archivo mostrar, etc) y envía trabajos a los trabajadores (a los que estén bloqueados, esperando entradas)
- Los trabajadores sólo esperan trabajos del despachador, y se encargan de generar la página (desde la caché, el disco, o generándola desde código) y la envían al cliente
Modelo sin hilos
Es posible un modelo de servidor web sin hilos, si se tiene acceso a instrucciones de disco sin bloqueo.
Este diseño se conoce como máquina de estados finitos
- Cuando hay que ir a buscar una página al disco, el servidor registra el estado de la petición en una tabla y pasa a atender el siguiente evento
- Cuando el disco encontró el archivo envía una interrupción
- El Servidor vuelve a dejar lo que hacía, completa la petición de la tabla con los datos y la borra
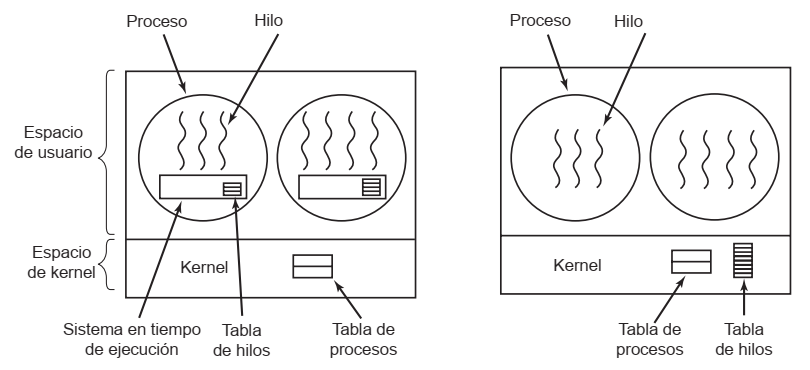
Comparación entre procesos e hilos
Estructuras en memoria
-
Esta es la información que se guarda en las "tablas de procesos e hilos"

-
Y la implementación de hilos de usuario (izquierda) y de kernel (derecha) cambia dónde se guarda esta tabla, y la planificación de la ejecución
- En modo usuario: El SO planifica cada proceso a ejecutar, y cada proceso luego planifica sus hilos
- En modo kernel: Hay una única planificación, el SO planifica globalmente todos los hilos de todos los procesos (como si cada hilo fuera un proceso en un SO sin hilos)