Cliente: Elemento de la red que solicita información. Proporciona una GUI
Interfaz de programación de aplicaciones (API): Conjunto de programas y funciones que permiten a un cliente y servidor intercambiar datos fácilmente
Middleware: Conjunto de controladores, APIs y software adicional que mejora la conectividad
Base de datos relacional: Una base de datos en la que se accede a información por filas
Lenguaje Estructurado de Consultas (SQL)
Red
Servidor: Una computadora de cualquier tipo, que atiende peticiones de red y brinda información a los solicitantes (clientes)
Características:
El sistema es abierto y modular
Se centralizan las bases de datos
El usuario tiene control sobre su computadora
Gestión y seguridad son de alta prioridad
Aplicaciones cliente/servidor
Se distribuyen las tareas entre el servidor y el cliente
El software de comunicaciones (principalmente el protocolo TCP/IP) permite que interactúen estos dos, dándoles las bases para las apps distribuidas
El principal factor es la forma de la interacción con el sistema de parte del usuario
Se suele optar por una GUI
Tipos de apps
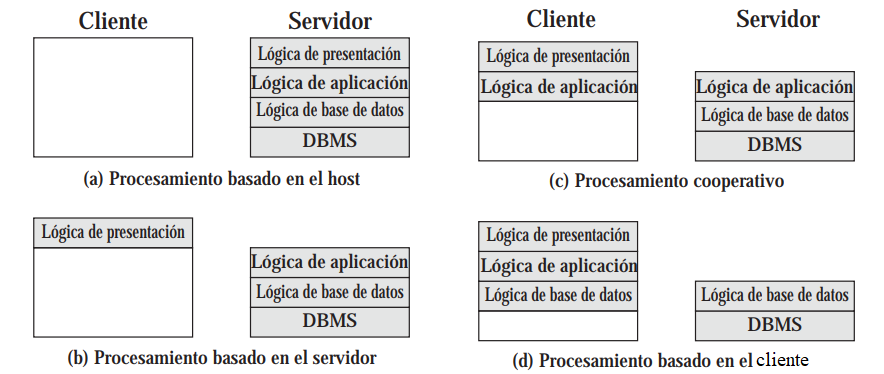
Hay distintas implementaciones de procesamiento, que definen cómo se divide el trabajo entre el cliente y el servidor:
Basado en el host: Se usa en entornos mainframe, y el servidor hace todo el trabajo
Basado en el servidor: El cliente sólo se encarga de presentar la interfaz al usuario, el servidor hace todas las lógicas de negocio
Basado en el cliente: Al contrario que el anterior, el cliente se encarga de todo lo que pueda
Esto excluye la validación de datos, y la lógica de bases de datos
Cooperativo: Ambas partes se distribuyen el trabajo de la forma más eficiente posible
Arquitectura de tres capas
En lugar de haber sólo una capa de cliente y una capa de servidor, ahora hay dos capas de servidor: una capa central y un servidor en segundo plano (backend)
Estos servidores de capa central suelen ser pasarela del cliente al backend: balanceando cargas (comunicando el cliente con el servidor con el CPU más libre), convirtiendo entre protocolos de comunicación, combinando datos de distintas fuentes, etc
Apps de bases de datos
La interacción es mediante transacciones (que incluyen una petición y una respuesta)
El servidor tiene un gestor de bases de datos (DB) y los clientes reciben información de éste y la formatean para el usuario
Toda la lógica está del lado del cliente
El servidor sólo se encarga de manejar la DB
Middleware
Middleware: Un software intermediario que permite o facilita la comunicación o intercambio de datos entre dos aplicaciones o sistemas
Proporciona una interfaz común y estandarizada que permite esconder los detalles de implementación de cada sistema
Servicios de orquestación (p.ej.: Docker, Kubernetes)
Entre otros...
Hay distintos tipos de middleware para los distintos usos (MW de mensajería, de integración, de bases de datos, etc)
Ventajas
El uso de Middleware puede mejorar el rendimiento y escalabilidad de los sistemas
Pueden proporcionar servicios de gestión y monitorización
Paso de mensajes distribuido
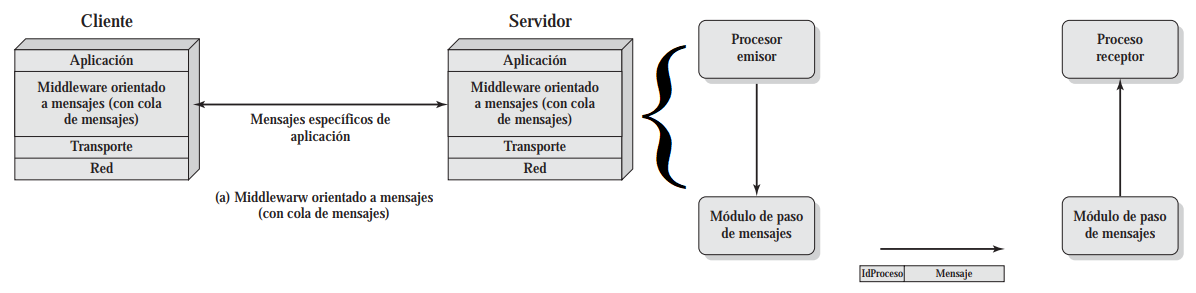
Como los sistemas de procesamiento distribuidos se componen de varias computadoras separadas pero trabajando en conjunto, los procesos no pueden compartir memoria principal. Por esto, deben usar técnicas basadas en el paso de mensajes para compartirse información o mandatos.
Se usa un middleware orientado a mensajes, un módulo del SO o de las aplicaciones propias (compatibles entre sí), para manejar el envío y recepción de mensajes
Sólo se necesitan dos funciones: send y receive
Un mensaje se compone de una primitiva (que especifica la función a realizar) y los parámetros (datos a procesar e info. de control)
Un proceso cliente envía mediante el MW un mensaje con la petición de un servicio (puede ser leer un fichero, imprimir cierta información)
El cliente usa la primitiva send, especificando en los parámetros el id de proceso destinatario y el contenido del mensaje
El proceso servidor recibe la petición y realiza la acción que venía en el mensaje
Fiable o no fiable
Un servicio de paso de mensajes fiable garantiza la entrega si es posible
Se usan protocolos de transporte fiables (como TCP) y hacen comprobación de errores, acuse de recibo, retransmisión, reordenamiento de mensajes, etc.
No necesitan una comprobación de que el mensaje fue enviado
! Son más lentos
Un servicio no fiable envía el mensaje por la red y no se le indica el éxito/fracaso
$ Reduce la complejidad y la sobrecarga de procesamiento
Bloqueante o no bloqueante
Cuando se procesan primitivas no bloqueantes o asincrónicas el SO devuelve el control al proceso tan pronto como el mensaje se ha puesto en la cola
$ Permiten un uso eficiente y flexible de los servicios de paso de mensajes
! Es difícil de implementar este tipo de primitivas
Cuando se usan primitivas bloqueantes o sincrónicas:
Un send no devuelve el control hasta que el emisor transmitió el mensaje (en el caso de un servicio no fiable) o hasta que se haya recibido el acuse de recibo (si el servicio es fiable)
Un receive no devuelve el control hasta que se haya copiado al buffer correspondiente
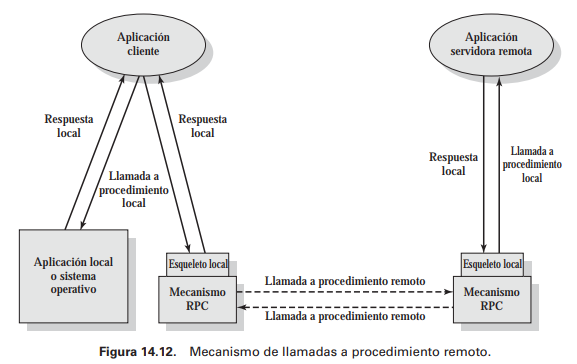
Llamadas a procedimiento remoto
Permiten a dos aplicaciones en distintas máquinas interactuar usando llamadas a procedimientos como si fueran procedimientos locales
Ventajas
Es una abstracción estandarizada ampliamente usada y aceptada
Permite especificar interfaces remotas como operaciones con nombre y parámetros con tipos de datos
Por esto, el código de comunicación puede ser escrito programáticamente
Por esto, los módulos cliente y servidor son muy portables entre distintas computadoras y SO
Enlace cliente-servidor
Se forma un enlace cuando dos apps se conectan lógicamente y están preparadas para intercambiar datos
El enlace especifica cómo se establece la relación entre procedimientos remotos y el programa llamante
Un enlace no permanente significa que la conexión lógica se cerrará apenas se devuelvan los valores del procedimiento llamado
$ El enlace no permanente es importante porque mantener una conexión abierta implica gastar recursos para intercambiar información de estado en ambos extremos
! Abrir conexiones es costoso, este tipo de enlace no es bueno para procedimientos llamados frecuentemente
Los enlaces persistentes se mantiene abierta para transmitir futuras llamadas
Clusters
Un conjunto de computadoras (nodos) que trabajan juntos como si fueran una sola entidad.
Están conectadas mediante una red de alta velocidad y comparten recursos y tareas de procesamiento.
En un cluster, cada nodo es independiente y puede trabajar en tareas individuales, o participar de tareas paralelizadas
Los nodos pueden ser servidores físicos, máquinas virtuales, o contenedores
En los clusters, se usa un software de coordinación para administrar los recursos compartidos y las taras distribuidas
Ventajas
Favorece la alta disponibilidad (pues si se cae un nodo, puede ser reemplazado por otro)
Ejemplo de nodo caído (Cortesía de: SYSACAD)
Escalabilidad: Más nodos = más CPU para distribuir = más rendimiento
Procesamiento distribuido: Permite paralelizar tareas mucho más
Componentes de un cluster
Nodos
Interconexión (red)
P.Ej.: Ethernet, Fiber Channel, InfiniBand
Software de gestión
Coordina el cluster: programando tareas, asignando recursos, monitoreando el rendimiento, detectando errores